本文基于2014年的经典论文:Generative Adversarial Networks
字面理解
- Generative Adversarial Nets
生成对抗网络通过对抗过程来评估一个生成模型。
GAN同时训练两个模型,一个产生模型G,一个判别模型D。
产生式模型G负责模拟数据的真实分布,判别式模型负责判断数据是来自训练数据还是生成数据。
G的目标就是要使D犯错误,判别不出真伪;D的目的就是要尽可能区分出真伪来,这样一来二去,两者形成了对抗过程,最终共同进步。最终的目的是得到产生模型G,判别模型D只是训练过程的副产品。

感性理解
现实生活中,一个很好的比方就是,我们想要造假币(但是不知道真币是什么样的),那么我们只能通过执法者的反馈,才知道我们造的假币到底够不够真。GAN网络里既有造假者,也有执法者,一来二去,执法者辨识力越来越高,造假者的造假技术也越加成熟,最终我们得到了一个火眼金睛的执法者,但是也得到了能以假乱真的造币工艺。事实上,执法者是网络的副产品,我们真正需要得到的是造币工艺,这就是对GAN的感性认识。(GAN学习笔记(一)初探GAN–CSDN)
模型认识
理论推导 Theoretical reults
理论推到基于3个假设:
- 训练时间是无限的
- (生成器和判别器)模型的能力是无限的
- 直接更新生成器的分布
基于以上假设GAN可以得出以下结论:
即不论初始值如何,GAN最终都必然会达到均衡。
价值函数 Value Function
GAN的目标函数是这样的:

GAN的训练是价值函数最大化和最小化的交替游戏:
其中Pdata是真实数据,Pz是生成数据。
当我们训练判别器D时,我们希望真实数据的判别值越大越好。同时我们希望对生成数据的判别值越小越好,所以也是越大越好。训练中使用梯度上升,使价值函数的值越来越高。
同理,当我们要训练生成器G时,就希望价值函数的值越小越好,即使用梯度下降来训练生成器的参数。
两个模型相对抗,最后达到全局最优。
训练过程
G可以把噪声z映射到真实样本x的特征空间,得到G(z)。一开始, 虽然G(z)和x是在同一个特征空间里的,但它们分布的差异很大,这时,承担鉴别真实样本和虚 假样本的模型D性能也不强,它很容易就能把两者区分开来,而随着训练的推进,虚假样本的分布逐渐与真实样本重合,D虽然也在不断更新,但也已经力不从心了。
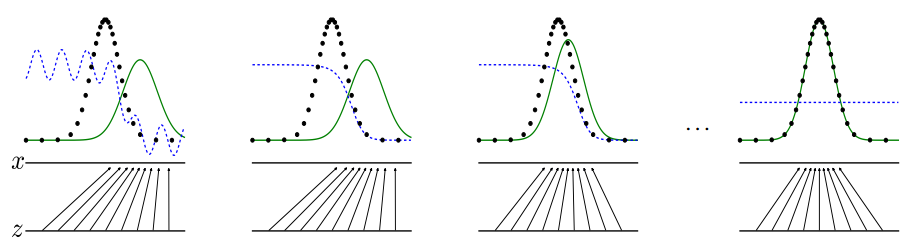
训练算法
首先固定G,单独训练D,为了让D得到充分训练,有的时候要迭代多次。本论文中每一轮迭代D只训练一次。D训练完毕后,固定D,训练G,如此循环。训练的方式是反向传播算法。

全局最优为pg=pdata的证明
固定G,D的最优解如下:

目标函数可以化简为如下形式:
a*log(y) + b*log(1-y);
该函数的最优解为a/(a+b).最小化部分可以重新定义为:

通过公式5和公式6可以证明,当pg=pdata的时候达到全局最优,此时D无论对真实样本还是虚假样本,输出都是0.5.
收敛性证明
- 基于G和D的能力无穷与训练时间无限的假设,可以证明pg能够收敛到pdata。
- 但是实际情况G的有限参数做训练,所以不能够保证收敛性,缺乏理论依据。
- 从实际应用可以证明该模型的有效性。
实验
评价实验结果:
论文给出的方法是高斯parzen窗法进行密度估计,先用真实样本给出高斯parzen概率密度函数,再计算虚假样本在这个分布中的密度,密度越大表示越接近真实值。
下表是给出了论文方法在MNIST和TFD两个数据集上的实验结果。
表格中每一格左侧的是我们需要的指标,右侧是通过交叉验证求得的高斯parzen窗计算时需要的参数。
为了证明生成图像不是单纯的记忆训练样本集,而是通过学习特征得到的,文章给出了一些实验结果。
从结果总可以看出,当样本维度较高时,效果就会下降。
下图展示了在生成模型空间差值得到的结果。
分析总结
GAN优势很多
- 根据实际的结果,看上去产生了更好的样本;
- GAN能训练任何一种生成器网络;
- GAN不需要设计遵循任何种类的因式分解的模型,任何生成器网络和任何鉴别器都会有用;
- GAN无需利用马尔科夫链反复采样,无需在学习过程中进行推断,回避了近似计算棘手的概率的难题。
GAN主要存在的以下问题
不收敛(non-convergence)的问题
网络难以收敛,目前所有的理论都认为GAN应该在纳什均衡上有很好的表现,但梯度下降只有在凸函数的情况下才能保证实现纳什均衡。
难以训练:崩溃问题(collapse problem)
GAN模型被定义为极小极大问题,没有损失函数,在训练过程中很难区分是否正在取得进展。GAN的学习过程可能发生崩溃问题(collapse problem),生成器开始退化,总是生成同样的样本点,无法继续学习。当生成模型崩溃时,判别模型也会对相似的样本点指向相似的方向,训练无法继续。
无需预先建模,模型过于自由不可控
与其他生成式模型相比,GAN这种竞争的方式不再要求一个假设的数据分布,即不需要formulate p(x),而是使用一种分布直接进行采样sampling,从而真正达到理论上可以完全逼近真实数据,这也是GAN最大的优势。然而,这种不需要预先建模的方法缺点是太过自由了,对于较大的图片,较多的 pixel的情形,基于简单 GAN 的方式就不太可控了(超高维)。在GAN[Goodfellow Ian, Pouget-Abadie J] 中,每次学习参数的更新过程,被设为D更新k回,G才更新1回,也是出于类似的考虑。
GAN的一些应用
字体生成

图像生成
From photo to Emoji
domain-transfer-network-github